글
psql to 'postgres'
말입니다 ..
이런 명령어 쓰는 ..
? : 도움말
a : 필드 정렬자 토글
C : html3 캡션 설정
c : 데이터베이스에 접속
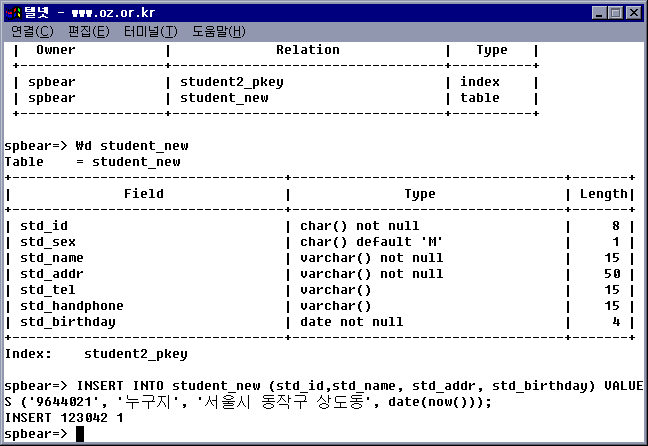
d : 현재 데이터베이스의 전체 테이블, 또는 특정 테이블 출력
di : 데이터베이스 내부의 인덱스만 출력
ds : 데이터베이스 내부의 시퀀스만 출력
dt : 데이터베이스 내부의 테이블만 출력
e : 현재 버퍼에 있는 질의어나 파일을 편집
f : 필드 구분자 변경 (보통은 '|')
h : SQL 명령어에 대한 문법적 도움말 출력
H : 질의의 결과를 html3 으로 출력할지의 여부 결정
i : 외부 파일에서 질의를 읽어서 실행함
l : 시스템의 모든 데이터베이스를 출력
p : 현재의 질의 버퍼를 출력
q : 종료
r : 질의 버퍼를 청소
t : 헤더정보와 행의 갯수를 출력할지의 여부 결정
z : 현재의 허용/취소 권한 출력
! : 쉘 명령어 실행
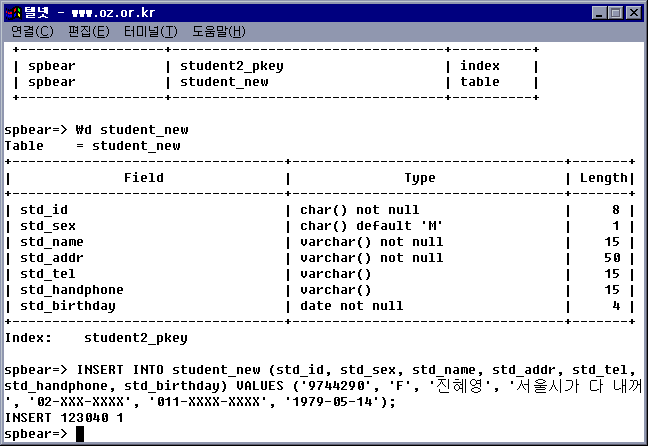
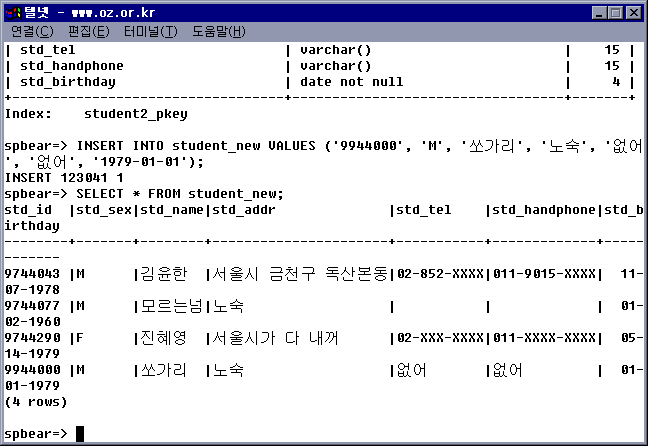
에서 말이죠, \c 를 이용해서 데이터 베이스까지 접속은 합니다.
접속하면 이렇게 뜨죠
testdb-#
여기서 말인데, \i 를 이용하면 외부 질의를 실행하게 된다는데,
외부 파일을 어떻게 읽어 드리게 합니까?
testdb-#\i test.sql
이렇게 하니까 파일 디렉토리를 찾을수 없다고 하는데 .. ;
저, sql 파일은 복구할 dump 파일을 확장자만 바꾼것임.
psql 외부옵션
psql 모니터링 프로그램은 아주 유용한 외부옵션을 많이 제공한다. 이걸 사용하면 쉘스크립트로 PostgreSQL를 사용한 CGI 프로그램을 간단하게 짤 수 있다.
-c 질의어 : psql 명령행으로 들어가지 않고 질의어만 전달하여 작업할 수 있다.
간단한 PostgreSQL작업에 유용하다.
-d 디비이름 : 접속할 데이터 베이스를 지정한다.
-e : backend로 보낸 질의어를 echo 한다.
-f 파일이름 : psql 내부에서 \i 명령을 사영하듯이, 외부에서도 SQL 질의어가 담긴
파일을 지정하여 실행할 수 있다
-H 호스트 이름 : postmaster 가 수행되고 있는 호스트에 접속한다 기본값은
localhost 이다.
-l : 사용가능한 데이테 베이스 목록을 출력한다.
-n : psql 내부 명령행에서 readline 라이브러리를 사용하지 않는다.
한글입력에 문제가 있을 때 사용할 수 있다.
-p 포트 : postmaster 가 돌아가고 있는 인터넷 tcp 포트를 지정한다.
기본값은 5432이다.
-q : 여러 가지 부가적인 메시지를 출력하지 않도록 한다.
-s : 싱글 스텝모드로 psql을 실행한다. 질의어를 실행하기 전에 엔터키를 한번더
쳐야 한다. 조심해야 할 작업에 사용할 수 있다.
쉘에서 어떠한 목적으로 psql 내부에 들어가지 않고 작업을 할 수 있다.
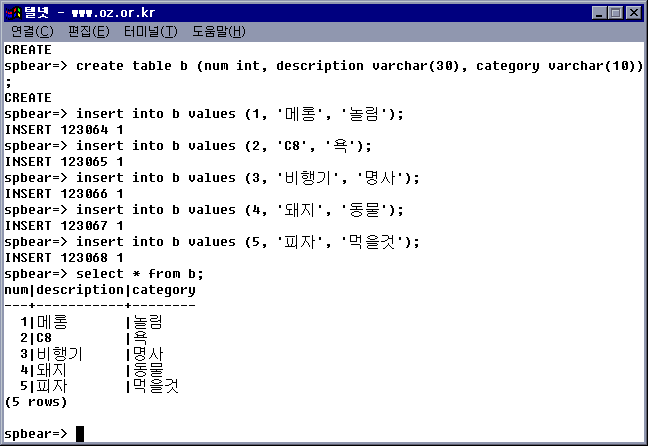
$ psql mydb -e -c "select * from 날씨"
다음호에서는 실제적인 업무에서 사용될 법한 좀더 복잡한 데이터 베이스를 PostgreSQL로 다루어 보면서 활용방안을 살펴보겠다.
'PostgreSQL' 카테고리의 다른 글
| 공개용 데이터베이스 서버 PostgreSQL (3) (0) | 2009.06.30 |
|---|---|
| 공개용 데이터베이스 서버 PostgreSQL (2) (0) | 2009.06.30 |
| [PostgreSQL] \? for help width psql commands (0) | 2008.04.24 |
| Postgresql 프로그래밍 (0) | 2008.04.23 |
| UNION, INTERSECT, EXCEPT (0) | 2007.09.19 |

RECENT COMMENT